With the advent of reactive programming and frameworks like Netflix' Hystrix, classic stability patterns like Nygard's Circuit Breaker Pattern have entered mainstream software development. The circuit breaker is used inside your clients to cut the connection to a collaborating system (the server) once you notice the server doesn't answer in a timely manner. This helps to prevent cascading failures - if your system is under high load, you open the circuit in the client to not launch a self-inflicted denial of service attack against your server.
Stateless services running in application servers typically don't require special measures to recover from overload conditions. But systems managing persistent state (for example relational databases) often don't recover at all and crash, which makes the circuit breaker extremely valuable. Configured properly, it prevents crashes and makes sure that the entire system recovers automatically once system load goes back to normal.
There's one drawback with the circuit breaker though: It's binary. Either the circuit is closed and everything is fine or it's open and you don't get any service from your servers even though they might still be able to respond to a fraction of the requests. This is why, in my opinion, circuit breakers should only be the last line of defense for your systems, but never the only one. Instead, it's a better idea to make sure your servers don't get overwhelmed in the first place. Assign clients a safe budget of parallel requests they may send to the servers. If that budget is chosen correctly, you will still get partial service in overload conditions. For those requests that exceed the budget, you can provide some alternative service (graceful degradation).
There are several techniques to implement such a limited budget. The easiest solution is by working with a fixed-size connection pool. If your server is a database, you already have a connection pool you can tweak. In most high-performance systems outgoing connections are pooled, too. The downside is that connection pools don't work that well with mixed workloads. Some requests may be more expensive than others, but with a single pool, they are all treated the same, so assigning a safe budget may result in resource under-utilization.
Limiting parallelism using semaphores is a more powerful solution. You initialize the semaphore with a value N and each thread that needs to connect to the server decreases the semaphore's counter before sending the request. If the semaphore reaches zero, no new connections are permitted until a thread returns its permits by incrementing the counter. That way, no more than N threads access the server at the same time. Threads requiring more expensive requests simply acquire more permits, making the system very flexible.
An alternative solution that I prefer is using a rate limiter. Network engineers have used rate limiters for a long time to impose limits on bandwidth and burstiness so devices like VoIP phones work reliably on busy local networks. The concept is applicable to other domains as well, not just for traffic shaping. In our context, a rate limiter is configured with a fixed rate of N permits per second. Before sending a request, a thread acquires permits from the rate limiter, causing it to block if no permits are available. The advantage over semaphores is that the thread doesn't have to return its permits - permits are refilled automatically with a rate of N permits per second, making it easier to implement. Google Guava has an implementation that works quite well.
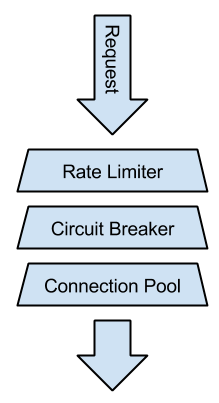
Both the semaphore approach and the rate limiter can be implemented using a decorator or adapter to your connection pool. In most cases, threads trying to acquire a permit should time out relatively quickly and not block indefinitely. Failing fast is often better than having all your worker threads waiting for too long, which is another one of Nygard's stability patterns.
When implementing one or more of these approaches, don't forget to monitor your systems closely to make sure you're aware when your system is in an overload condition. In a connection pool, always trigger a warning when the number of connections reach a configurable threshold. For semaphores and the rate limiter it's the same thing: Trigger warnings when threads can't acquire a permit. You might also want to monitor the time it takes to get permission.